数据库模块划分
关键语法
GROUP BY
- 满足 SELECT 子句中的列名必须为分组列或列函数
- 列函数对于 GROUP BY 子句定义的每一个组各返回一个结果
HAVING
- 通常与 GROUP BY 子句一起使用
- WHERE 过滤行,HAVING 过滤组
- 关键字的顺序:WHERE – GROUP BY – HAVING
索引相关内容
为什么要使用索引
全表扫描适用范围窄,借助字典的思想,使用索引可以加快查询速度。
什么样的字段可以作为索引
主键、唯一键等能使数据区分开的字段。
索引的数据结构
- 二叉查找树
- B - Tree
- B+ - Tree
- Hash 索引
MySQL 索引使用的数据结构主要有 BTree 索引和哈希索引。对于哈希索引,底层数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快。其余场景,建议选择 BTree 索引,MySQL 的 BTree 索引使用的是 B+Tree。
密集索引和稀疏索引的区别
- 密集索引文件中的每一个搜索码值都对应一个索引值。
- 稀疏索引文件只为索引码的某些值建立索引项。
InnoDB 存储引擎的必须仅有一个密集索引,其选取规则如下:
- 若一个主键被定义,该主键则作为密集索引;
- 若没有主键被定义,该表的第一个唯一非空索引作为密集索引;
- 若不满足以上条件,InnoDB 内部会生成一个隐藏主键。
非主键索引存储相关键位和其对应的主键值,包含两次查找。
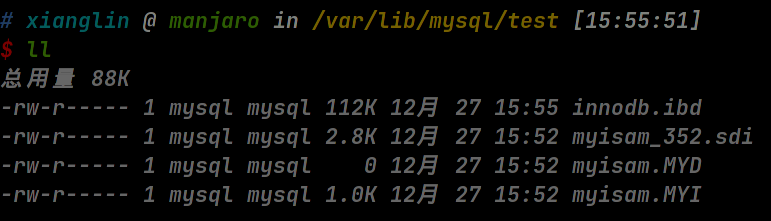
如图:表 test.innodb 使用 InnoDB 存储引擎,其数据和索引存储在文件 innodb.ibd 中;表 test.myisam 使用 MyISAM 存储引擎,其数据文件保存在 myisam.MYD 中,索引文件保存在 myisam.MYI 中。
如何定位并优化慢查询 SQL
- 根据慢日志定位慢查询 SQL;
- 使用 explain 等工具分析 SQL;
- 修改 SQL 或者尽量让 SQL 走索引。
慢查询相关配置
使用 show variables like '%query%'; 查询当前数据库对慢查询的配置,主要有以下几个参数:
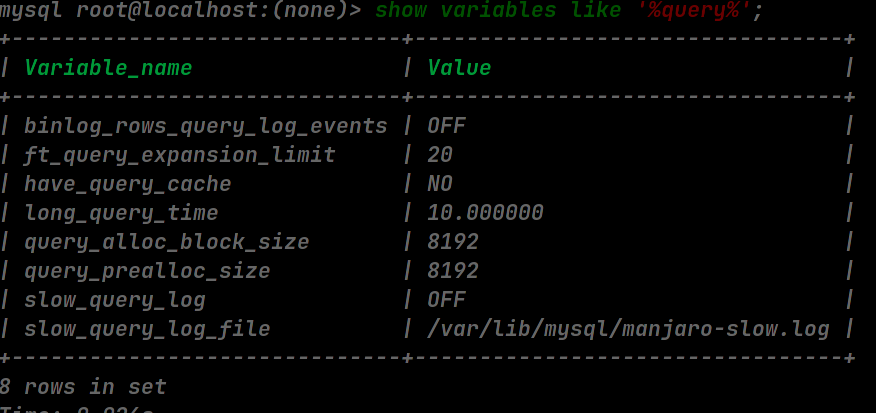
Variable_name | Value | 描述 |
|---|---|---|
show_query_log | OFF / ON | 是否记录慢SQL |
slow_query_log_file | /var/lib/mysql/*-slow.log | 慢日志文件路径 |
long_query_time | 10.0000 | 执行时间多长判定为慢 SQL |
可以修改 MySQL 的配置文件 /etc/mysql/my.cnf,修改这些参数,使其永久有效。
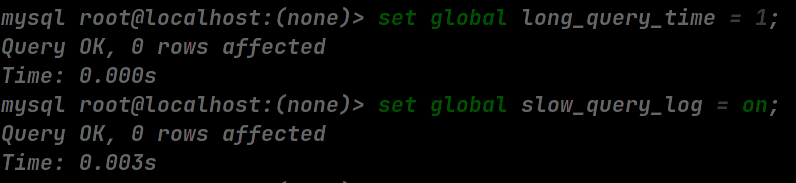
也可以通过设置全局变量的方式使其在 MySQL 服务重启前一直生效:
set global long_query_time = 1;
set global slow_query_log = on;
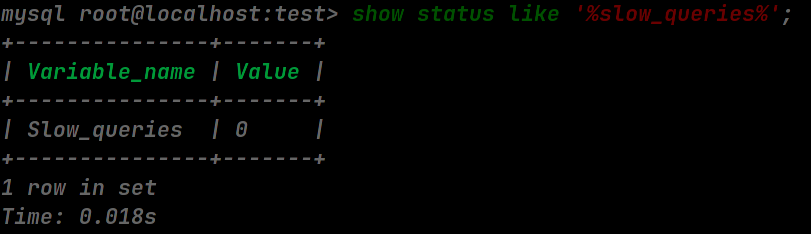
可以使用 show status like '%slow_queries%' 来查询当前会话的慢 SQL 数:
在慢查询日志 /var/lib/mysql/manjaro-slow.log 中查看慢 SQL 。
使用 explain 分析 SQL 执行计划:
explain select name from person_info_large order by name desc;

主要需要关注的字段有:
id:执行编号
type:访问类型
extra:查询优化器对查询计划的补充信息
联合索引的最作匹配原则
由多列组成的索引称为联合索引。
有如下表结构:
CREATE TABLE `person_info_large` (
`id` INT NOT NULL AUTO_INCREMENT,
`account` VARCHAR ( 10 ) DEFAULT NULL,
`name` VARCHAR ( 20 ) DEFAULT NULL,
`area` VARCHAR ( 20 ) DEFAULT NULL,
`title` VARCHAR ( 20 ) DEFAULT NULL,
`motto` VARCHAR ( 50 ) DEFAULT NULL,
PRIMARY KEY ( `id` ),
UNIQUE KEY `account` ( `account` ),
KEY `index_area_title` ( `area`, `title` )
) ENGINE = INNODB AUTO_INCREMENT = 196606 DEFAULT CHARSET = utf8;
索引 index_area_title 是对 area 和 title 两个字段建立的联合索引。考虑以下查询语句:
EXPLAIN SELECT
*
FROM
person_info_large
WHERE
area = 'nTtqWvRzVvuuYXBk5AFC'
AND title = 'lLrm20htGVVqRqJDWBU0';
EXPLAIN SELECT
*
FROM
person_info_large
WHERE
area = 'nTtqWvRzVvuuYXBk5AFC';
EXPLAIN SELECT
*
FROM
person_info_large
WHERE
title = 'lLrm20htGVVqRqJDWBU0';
前两个查询的分析结果为:

最后一个查询的分析结果为:

最左前缀匹配原则是指:
- MySQL 会一直向右匹配直到遇到范围查询(
>、<、between、like)就停止匹配。比如a = 3 and b = 4 and c > 5 and d = 6,如果建立(a, b, c, d)顺序的索引,则 d 是用不到索引的,如果建立(a, b, d, c)的索引则都可以用到,且 a b d 的顺序可以任意调整。 =和in可以乱序,比如a = 1 and b = 2 and c = 3建立(a, b, c)索引可以任意顺序,MySQL 的查询优化器会优化成索引可以识别的形式。
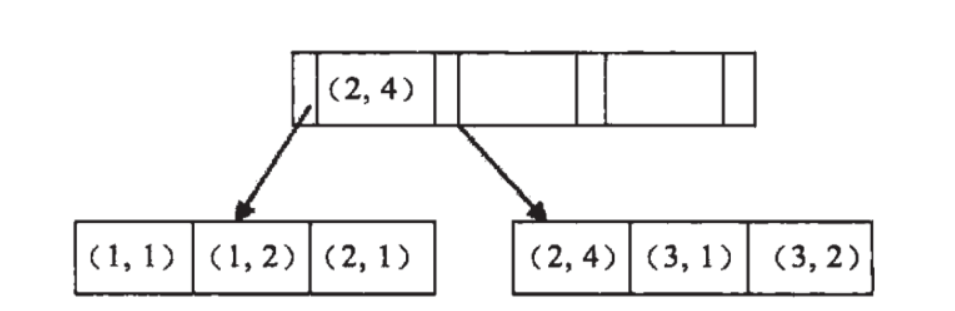
最左匹配原则的成因:如图,创建联合索引时,数据库依据联合索引最左的字段来构建 B+Tree,即会按索引字段顺序对数据排序。比如 a 的值是有序的: 1,1,2,2,3,3 ,B 的值是无序的。当 a 值相等时,b 的值是有序的。所以最左匹配原则遇上范围查询就会停止,因为在一个范围中,剩下的字段不是有序的,剩下的字段都无法使用索引。
索引是建立得越多越好吗
- 数据量小的表不需要建立索引,建立索引会带来额外的开销。
- 数据变化时需要维护索引,因此更多的索引意味着更多的维护成本(参照同理)。
- 更多的索引意味着需要更多的空间。
锁相关内容
MySQL MyISAM 和 InnoDB 存储引擎
查看存储引擎相关的命令:
查看 MySQL 提供的所有存储引擎
show engines;

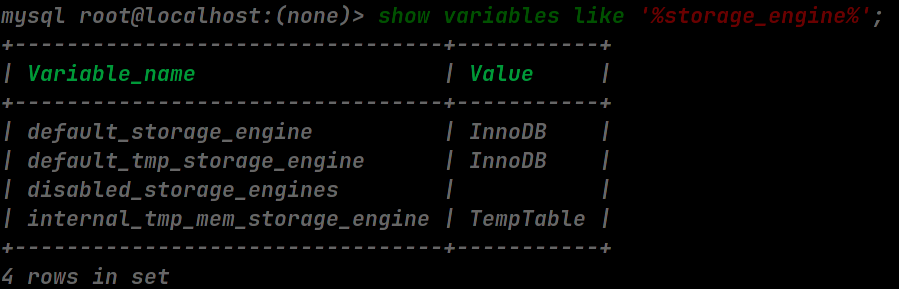
查看默认的存储引擎
show variables like '%storage_engine%';
查看表相关内容
show table status like 'shop_info_small';

MyISAM 和 InnoDB 的区别
MySQL 5.5 之前使用 MyISAM 作为默认的数据库存储引擎,MyISAM 提供了全文索引、压缩和空间函数等特性,但是不支持事务和行级锁。MySQL 5.5 版本时引入 InnoDB 作为其默认的存储引擎。主要的区别有:
- 是否支持行级锁:MyISAM 只有表级锁,而 InnoDB 默认为行级锁,支持表表级锁。
- 对事务和安全恢复的支持:MyISAM 强调性能,故不提供事务支持。InnoDB 支持事务,外部键等功能,具有事务、回滚和崩溃修复能力。
- 是否支持外键:MyISAM 不支持外键,InnoDB 支持。
MyISAM 与 InnoDB 关于锁方面的区别
MyISAM 默认是表级锁,不支持行级锁。
InnoDB 默认是行级锁,也支持行级锁。
表级锁: MySQL 中锁定粒度最大的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低, MyISAM 和 InnoDB 引擎都支持表级锁。
行级锁: MySQL 中锁定粒度最小的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
手动锁定表:
select * from table_name for update;
lock tables table_name read | write;
unlock tables;
MyISAM 适合的场景
- 频繁执行全表 count 语句。
- 对数据进行增删改的频率不高,查询非常频繁。
- 不需要事务。
InnoDB 使合的场景
- 数据增删改查都相当频繁。
- 可靠性要求比较高,需要使用事务。
数据库锁的分类
- 按锁的粒度划分,可分为表级锁、行级锁、页级锁
- 按锁级别划分,可分为共享锁、排它锁
- 按加锁方式划分,可分为自动锁、显示锁
- 按操作划分,可分为 DML 锁,DDL 锁
- 按使用方式划分,可分为乐观锁、悲观锁
数据事务的四大特性
原子性(Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部 完成,要么完全不起作用;
一致性(Consistency):执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是 相同的;
隔离性(Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务 之间数据库是独立的;
持久性(Durability):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据 库发生故障也不应该对其有任何影响。
事务并发访问引起的问题
- 更新丢失(Lost to modify,MySQL 所有事务隔离级别均已避免此类问题)
- 脏读(Dirty read):一个事务读到另一个事务未提交的事务。
- 不可重复读(Unrepeatable-read):在一个事务下多次读取同一记录得到的数据不一致。
- 幻读(Phantom read):事务 A 读取了多行,事务 B 在事务 A 未完成前对 A 读取范围内的数据做增删操作,导致事务 A 多次读取的记录数不一致的情况。
REPEATABLE READ 如何避免幻读
当前读和快照读
当前读:加了锁的 SQL 语句,读取的是记录的最新版本,且其它事务无法修改记录。
select ... lock in share mode;
select ... from update;
update
delete
insert
快照读:不加锁的非阻塞读,基于 MVCC 实现。
next-key 锁(行锁 + Gap 锁)
行锁
Gap 锁:如果 where 条件全部命中,则不会加 Gap 锁。
Gap 锁会用在非唯一索引和无索引的当前读中。