MyBatis 基础
MyBatis 介绍
- MyBatis 是优秀的持久层框架
- MyBatis 使用 XML 将 SQL 与程序代码解耦,便于维护
- MyBatis 学习简单,执行高效,是 JDBC 的延伸
MyBatis 开发流程
- 引入 MyBatis 依赖
- 创建核心配置文件
- 创建实体(Entity)类
- 创建 Mapper 映射文件
- 初始化 SessionFactory
- 利用 SQLSession对象操作数据
SqlSessionFactory
- SqlSessionFactory 是 MyBatis 的核心对象
- SQLSessionFactory 用于初始化MyBatis,创建 SQLSession 对象
- 应保证 SQLSessionFactory 全局唯一
SqlSession
- SQLSession 是MyBatis 操作数据库的核心对象
- SQLSession 使用 JDBC 与数据库交互
MyBatis 查询
MyBatis 日志框架
Mybatis 通过使用内置的日志工厂org.apache.ibatis.logging.LogFactory提供日志功能。内置日志工厂将会把日志工作委托给下面的实现之一:
org.apache.ibatis.logging.slf4j.Slf4jImplorg.apache.ibatis.logging.commons.JakartaCommonsLoggingImplorg.apache.ibatis.logging.log4j.Log4jImplorg.apache.ibatis.logging.log4j2.Log4j2Implorg.apache.ibatis.logging.jdk14.Jdk14LoggingImplorg.apache.ibatis.logging.nologging.NoLoggingImpl
MyBatis 内置日志工厂会基于运行时检测信息选择日志委托实现。它会(按上面罗列的顺序)使用第一个查找到的实现。当没有找到这些实现时,将会禁用日志功能。
MyBatis 查找日志的顺序定义在
org.apache.ibatis.logging.LogFactory中// 使用静态块加载日志框架 static { tryImplementation(LogFactory::useSlf4jLogging); tryImplementation(LogFactory::useCommonsLogging); tryImplementation(LogFactory::useLog4J2Logging); tryImplementation(LogFactory::useLog4JLogging); tryImplementation(LogFactory::useJdkLogging); tryImplementation(LogFactory::useNoLogging); } public static synchronized void useSlf4jLogging() { setImplementation(org.apache.ibatis.logging.slf4j.Slf4jImpl.class); }NoLoggingImpl中的所有方法都未实现,即为禁用日志功能。public class NoLoggingImpl implements Log { public NoLoggingImpl(String clazz) { // Do Nothing } @Override public void error(String s, Throwable e) { // Do Nothing } }可以在MyBatis 配置文件
mybatis-config.xml中使用setting标签来指定 MyBatis 的日志实现<configuration> <settings> ... <setting name="logImpl" value="LOG4J"/> ... </settings> </configuration>logImpl的可选值有:SLF4J、LOG4J、LOG4J2、JDK_LOGGING、COMMONS_LOGGING、STDOUT_LOGGING、NO_LOGGING,或者是实现了org.apache.ibatis.logging.Log接口且构造方法以字符串为参数的类完全限定名。private static void setImplementation(Class<? extends Log> implClass) { try { Constructor<? extends Log> candidate = implClass.getConstructor(String.class); Log log = candidate.newInstance(LogFactory.class.getName()); if (log.isDebugEnabled()) { log.debug("Logging initialized using '" + implClass + "' adapter."); } logConstructor = candidate; } catch (Throwable t) { throw new LogException("Error setting Log implementation. Cause: " + t, t); } }
MyBatis 动态 SQL
if
if 标签通常用于WHERE语句中,通过参数值来决定是否使用某个查询条件,也常用于UPDATE语句中判断是否更新某一个字段,还可以在INSERT语句中用来判断是否插入某个字段的值。
在WHERE条件中使用if
实现一个用户高级查询功能,根据输入条件去检索用户信息。当只输入用户名时,需要根据用户名进行模糊查询;只输入邮箱时,根据邮箱进行完全匹配;当同时输入用户名和邮箱时,用两个条件进行查询。
<select id="selectByUser" resultType="person.xianglin.simple.model.SysUser">
select id, user_name userName, user_password userPassword, user_email userEmail, user_info userInfo, head_img
headImg, create_time createTime
from sys_user
where 1 = 1
<if test="userName != null and userName != ''">
and user_name like concat('%', #{userName}, '%')
</if>
<if test="userEmail != null and userEmail != ''">
and user_email = #{userEmail}
</if>
</if>
</select>
if标签有一个必填属性test,test属性值是一个符合OGNL要求的判断表达式,表达式的结果可以是true或false,除此之外所有的非 0 值都是true,只有0为false。
- 判断条件
property != null或property == null:适用于任何类型的字段,用于判断属性值是否为空。 - 判断条件
property != ''或property == '':适用于String类型的字段,用于判断是否为空字符串。 and和or:当有多个判断条件时,使用and或or进行连接,嵌套的判断条件可以使用小括号分组,and相当于 Java 中的与&&,or相当于 Java 中的或||。
在UPDATE更新列中使用if
如果只更新有变化的字段,更新时不能将原来有值但没有变化的字段更新为空或null。
<update id="updateByIdSelective">
update sys_user set
<if test="userName != null and userName != ''">
user_name = #{userName},
</if>
<if test="userPassword != null and userPassword != ''">
user_password = #{userPassword},
</if>
<if test="userEmail != null and userEmail != ''">
user_email = #{userEmail},
</if>
<if test="userInfo != null and userInfo != ''">
user_info = #{userInfo},
</if>
<if test="headImg != null and headImg != ''">
head_img = #{headImg},
</if>
<if test="createTime != null and createTime != ''">
create_time = #{createTime,JDBC_TYPE=TIMESTAMP},
</if>
id = #{id}
where id = #{id}
</update>
在INSERT动态插入列中使用if
在插入操作时。如果某一列的参数值不为空,就使用传入的值,如果传入参数为空,就使用数据库中的默认值。使用if可以实现这种动态插入列的功能。
<insert id="insert2" useGeneratedKeys="true" keyProperty="id">
insert into sys_user(user_name,user_password
<if test="userEmail != null and userEmail != ''">
,user_email
</if>,user_info,head_img,create_time)
values(#{userName},#{userPassword}
<if test="userEmail != null and userEmail != ''">
,#{userEmail}
</if>
,#{userInfo},#{headImg,jdbcType=BLOB},#{createTime,jdbcType=TIMESTAMP})
</insert>
在INSERT中使用时需要注意,若在列部分增加if条件,则在 value部分也要增加相同的if条件,必须保证列和插入的值相对应。
choose、when、otherwise
if标签提供了基本的条件判断,但是无法实现if...else的逻辑。choose when otherwise标签可以实现这样的逻辑。choose元素中包含when和otherwise两个标签,一个choose中至少一个when,有0 个或 1 个otherwise。
进行如下查询:当参数 ID 有值时,优先使用 ID 查询,当 ID 没有值时判断用户名是否有值,如果有值就用用户名查询,如果用户名也没有值,就是 SQL 查询无结果。
<select id="selectUserByIdOrUserName" resultType="SysUser">
select * from sys_user
where 1 = 1
<choose>
<when test="id != null">
and id = #{id}
</when>
<when test="userName != null and userName != ''">
and user_name = #{userName}
</when>
<otherwise>
and 1 = 2
</otherwise>
</choose>
</select>
trim、where、set
where用法
where 标签的作用:如果该标签包含的元素中有返回值,就插入一个where;如果where后面的字符串是以AND和OR开头的,就将它们剔除。
修改上述 [在WHERE中使用if] 的 SQL 语句:
<select id="selectByUser" resultType="SysUser">
select * from sys_user
<where>
<if test="userName != null and userName != ''">
and user_name like concat('%', #{userName}, '%')
</if>
<if test="userEmail != '' and userEmail != null">
and user_email = #{userEmail}
</if>
</where>
</select>
set用法
set标签的作用:如果该标签包含的元素中有返回值,就插入一个set;如果set后面的字符串是以逗号结尾的,就剔除这个逗号。
修改上述 [在UPDATE中使用if] 的 SQL 语句:
<update id="updateByIdSelective">
update sys_user
<set>
<if test="userName != null and userName != ''">
user_name = #{userName},
</if>
<if test="userPassword != null and userPassword != ''">
user_password = #{userPassword},
</if>
<if test="userEmail != null and userEmail != ''">
user_email = #{userEmail},
</if>
<if test="userInfo != null and userInfo != ''">
user_info = #{userInfo},
</if>
<if test="headImg != null and headImg != ''">
head_img = #{headImg},
</if>
<if test="createTime != null and createTime != ''">
create_time = #{createTime,JDBC_TYPE=TIMESTAMP},
</if>
id = #{id}
</set>
where id = #{id}
</update>
set标签只解决了逗号问题,如果set元素没有内容,SQL 语句格式仍然有误,所以类似id =#{id}这样必然存在的赋值仍有保留的必要。
trim用法
where 和 set 标签的功能都可以用 trim 标签来实现,并且在底层就是通过 TrimSqlNode 实现的。
where 标签对应的 trim 实现如下:
<trim prefix="WHERE" prefixOverrides="AND | OR ">
...
</trim>
set标签对应的trim实现如下:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
trim标签有如下属性:
prefix:当trim元素包含内容时,会给内容增加prefix指定的前缀。prefixOverrides:当trim元素包含内容时,会把内容中匹配的前缀字符串去掉。suffix:当trim元素包含内容时,会给内容增加suffix指定的后缀。suffixOverrides:当trim元素包含内容时,会把内容中匹配的后缀字符串去掉。
foreach
SQL 语句中会使用IN关键字,例如id in (1, 2, 3),可以使用${ids}方式直接传参,但这种写法不能防止 SQL 注入,想要使用#{}的方式,就需要配合foreach标签使用。
foreach遍历对象可以分为两大类:Iterable类型和Map类型。
foreach实现in集合
<select id="selectByIdList" resultType="SysUser">
select * from sys_user
where id in
<foreach collection="list" open="(" close=")" separator="," item="id" index="i">
#{id}
</foreach>
</select>
foreach包含以下属性:
collection:必填,值为要迭代循环的属性名。item:变量名,值为从迭代对象中取出的每一个值。index:索引的属性名,在集合数组情况下为当前索引值,当迭代循环的对象时Map类型时,这个值为Map的key。open:整个循环内容开头的字符串。close:整个循环内容结尾的字符串。separator:每次循环的分隔符。
关于collection属性值的设置。分析DefaultSqlSession的源码:
private Object wrapCollection(final Object object) {
if (object instanceof Collection) {
StrictMap<Object> map = new StrictMap<Object>();
map.put("collection", object);
if (object instanceof List) {
map.put("list", object);
}
return map;
} else if (object != null && object.getClass().isArray()) {
StrictMap<Object> map = new StrictMap<Object>();
map.put("array", object);
return map;
}
return object;
}
foreach实现批量插入
<insert id="insertList" useGeneratedKeys="true" keyColumn="id" keyProperty="id">
insert into sys_user(user_name,user_password,user_email,create_time)
values
<foreach collection="list" item="user" separator=",">
(#{user.userName},#{user.userPassword},#{user.userEmail},#{user.createTime,jdbcType=TIMESTAMP})
</foreach>
</insert>
foreach实现动态UPDATE
<update id="updateByMap">
update sys_user
<set>
<foreach collection="_parameter" separator="," item="value" index="key">
${key} = #{value}
</foreach>
</set>
where id = #{id}
</update>
bind
bind标签可以使用OGNL表达式创建一个变量并将其绑定到上下文中。如上面所述的selectByUser 方法中的like查询条件
<if test="userName != null and userName != ''">
and user_name like concat('%', #{userName}, '%')
</if>
改为bind方式
<if test="userName != null and userName != ''">
<bind name="userNameLike" value="'%' + userName + '%'"/>
and user_name like #{userNameLike}
</if>
name:绑定到上下文的变量名value:OGNL表达式
MyBatis缓存技术
一般提到 MyBatis 缓存的时候,都是指二级缓存。一级缓存默认启用,且不能控制。
一级缓存
MyBatis 的一级缓存存在于 SqlSession 的生命周期中,在同一个SqlSession 中查询时,MyBatis 会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个 Map 对象中。如果同一个 SqlSession 中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当 Map 缓存对象中已经存在该键值时,则会返回缓存中的对象。任何的 INSERT、 UPDATE、DELETE 操作都会清空一级缓存。也可以在select标签中添加flushCache="true"元素,让 MyBatis 在查询数据前清空当前的一级缓存。
一级缓存实现
一级缓存对象:
org.apache.ibatis.cache.impl.PerpetualCachepublic class PerpetualCache implements Cache { // 一级缓存使用 Map 实现 private Map<Object, Object> cache = new HashMap<Object, Object>(); }执行查询时一级缓存实现
public <E> List<E> query(...){ // ... // 尝试从一级缓存中获取结果 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 没有存在一级缓存中时,从数据库查询 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } // ... } private <E> List<E> queryFromDatabase(...) { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { // 执行数据库查询 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } // 将查询结果存于本地缓存 localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }flushCache配置
flushCache后MappedStatement对象中flushCacheRequired属性值由false变为true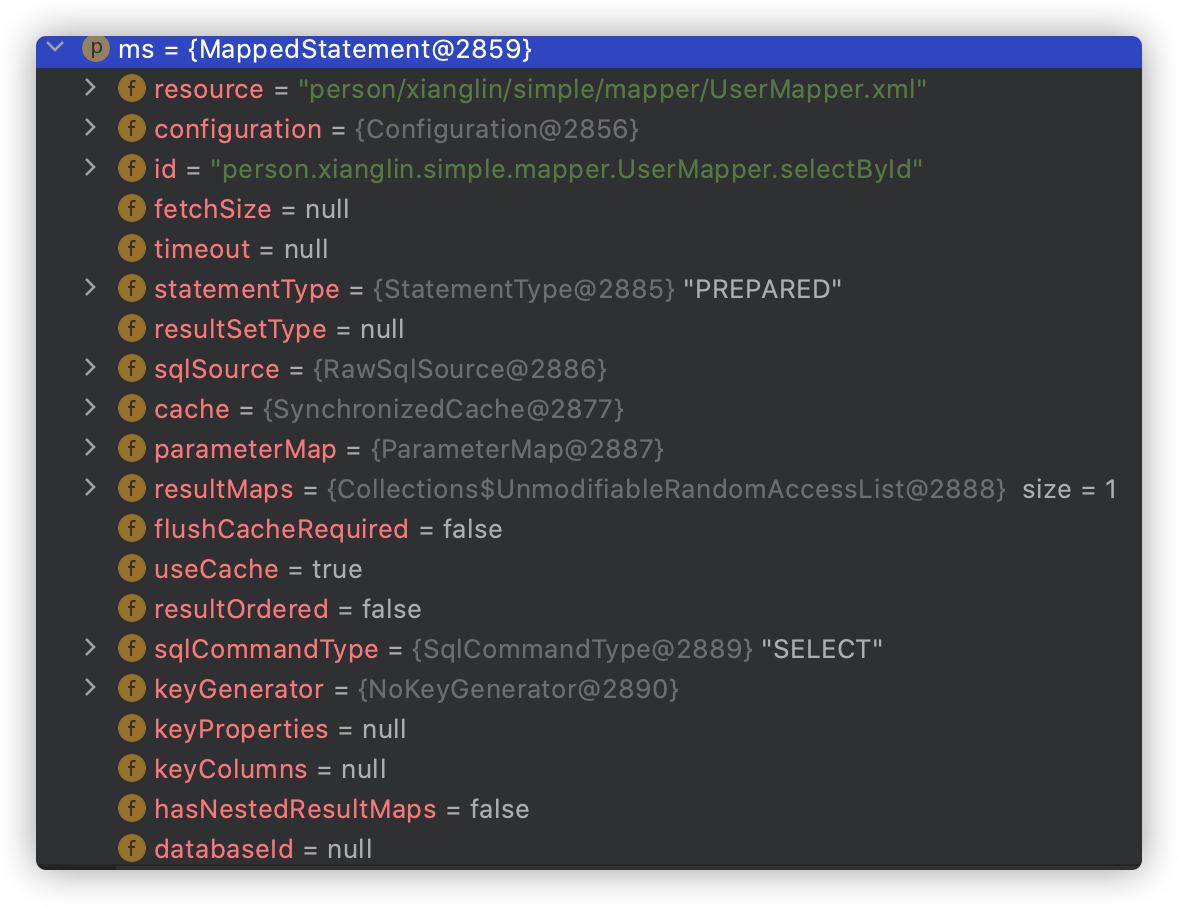

对应代码段在
org.apache.ibatis.executor.BaseExecutor#query中if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } // 清除一级缓存 // 最后调用的方法时 Map 的 clear() public void clearLocalCache() { if (!closed) { localCache.clear(); localOutputParameterCache.clear(); } }
二级缓存
MyBatis 的二级缓存非常强大,它不同于一级缓存只存在于 SqlSession 的生命周期中, 而是可以理解为存在于 SqlSessionFactory 的生命周期中。当存在多个 SqlSessionFactory 时,它们的缓存都是绑定在各自对象上的,缓存数据在一般情况下是不相通的。只有在使用如 Redis 这样的缓存数据库时,才可以共享缓存。
配置二级缓存
MyBatis 全局配置 setting中有一个参数cacheEnabled,是二级缓存的全局开关,默认值为true。
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
MyBatis 的二级缓存和命名空间绑定的,即二级缓存需要配置在Mapper.xml映射文件或者配置在Mapper.java接口中。
Mapper.xml中配置二级缓存
在保证二级缓存的全局配置开启的情况下,给某个命名空间开启二级缓存只需要在Mapper.xml中添加<cache/>元素即可。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="tk.mybatis.simple.mapper.RoleMapper">
<cache/>
<!--其他配置-->
</mapper>
默认的二级缓存会有如下效果:
映射语句中的所有
SELECT语句将会被缓存。映射语句中所有的
INSERT、UPDATE、DELETE语句会刷新缓存。缓存会使用
Least Recently Used(最近最少使用的)算法来收回。根据时间表属性缓存
缓存存储集合或对象的 1024 个引用。
缓存会被视为
read/write的,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其它调用者或线程所做的潜在修改。<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
对可配置属性的解释如下:
eviction:(回收策略)LRU(最近最少使用的):移除最长时间不被使用的对象,默认值。FIFO(先进先出):按对象进入缓存的顺序来移除。SOFT(软引用):移除基于垃圾回收器状态和软引用规则的对象。WEAK(弱引用):更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval(刷新间隔)。设置为任意的正整数,代表一个合理的毫秒形式的时间段。默认情况下不设置,即没有刷新间隔,缓存仅在调用语句时刷新。size(引用数目)。默认值是 1024.readOnly(只读)。可以设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改。可读写的缓存会通过序列化返回缓存对象的拷贝。
Mapper接口中配置二级缓存
当只使用注解方式配置二级缓存时,需要增加如下配置。
@CacheNamespace(
eviction = FifoCache.class,
flushInterval = 60000,
size = 512,
readWrite = true
)
public interface RoleMapper {
// other code
}
当同时使用注解方式和 XML 映射文件时,如果同时配置了上述的二级缓存,会抛出如下异常
Caches collection already contains value for tk.mybatis.simple.mapper.RoleMapper
这时候应该使用参照缓存,参照缓存配置如下:
@CacheNamespaceRef(RoleMapper.class)
public interface RoleMapper {
// other code
}
Mapper 接口可以通过注解引用 XML 映射文件或者其他接口的缓存,在 XML 中也可以配置参照缓存,如下配置:
<cache-ref namespace="tk.mybatis.simple.mapper.RoleMapper"/>
使用二级缓存
当配置缓存为可读写时,MyBatis 使用SerializedCache序列化缓存来实现可读写缓存类,并通过序列化和反序列化来保证通过缓存获取数据时,得到的是一个新的实例。因此,要求被序列化的对象实现Serializable接口。如果配置为只读缓存,MyBatis 就会使用 Map 来存储缓存值,这种情况下,从缓存中获取的对象就是同一个实例。
@Test
public void testL2Cache() {
SqlSession sqlSession = getSqlSession();
SysRole role1;
try {
RoleMapper mapper = sqlSession.getMapper(RoleMapper.class);
role1 = mapper.selectById(1L);
role1.setRoleName("NEW NAME");
SysRole role2 = mapper.selectById(1L);
Assert.assertEquals("NEW NAME", role2.getRoleName());
Assert.assertEquals(role1, role2);
} finally {
sqlSession.close();
}
System.out.println("开启新的 SQLSession");
sqlSession = getSqlSession();
try {
RoleMapper mapper = sqlSession.getMapper(RoleMapper.class);
SysRole role2 = mapper.selectById(1L);
Assert.assertEquals(role2.getRoleName(), "NEW NAME");
Assert.assertNotEquals(role2, role1);
SysRole role3 = mapper.selectById(1L);
Assert.assertNotEquals(role2, role3);
} finally {
sqlSession.close();
}
}
测试执行的日志为:
DEBUG [main] - Cache Hit Ratio [person.xianglin.simple.mapper.RoleMapper]: 0.0
DEBUG [main] - ==> Preparing: select id,role_name roleName,enabled, create_by createBy,create_time createTime from sys_role where id = ?
DEBUG [main] - ==> Parameters: 1(Long)
TRACE [main] - <== Columns: id, roleName, enabled, createBy, createTime
TRACE [main] - <== Row: 1, 管理员, 1, 1, 2016-04-01 17:02:14.0
DEBUG [main] - <== Total: 1
DEBUG [main] - Cache Hit Ratio [person.xianglin.simple.mapper.RoleMapper]: 0.0
开启新的 SQLSession
DEBUG [main] - Cache Hit Ratio [person.xianglin.simple.mapper.RoleMapper]: 0.3333333333333333
DEBUG [main] - Cache Hit Ratio [person.xianglin.simple.mapper.RoleMapper]: 0.5
集成EhCache缓存
MyBatis 项目开发者最早提供了 EhCache 的 MyBatis 二级缓存实现, 该项目名为 ehcache-cache,地址是 https://github.com/mybatis/ehcache-cache。
添加项目依赖
在
pom.xml文件中加入如下依赖<dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.2.1</version> </dependency>配置 EhCache
在 resources 目录下新增
ehcache.xml文件<?xml version="1.0" encoding="UTF-8" ?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="ehcache.xsd" updateCheck="false" monitoring="autodetect" dynamicConfig="true"> <diskStore path="C:\Users\xianglin\project\idea-workspace\mybatis\cache"/> <defaultCache maxElementsInMemory="3000" eternal="false" copyOnRead="true" copyOnWrite="true" timeToIdleSeconds="3600" timeToLiveSeconds="3600" overflowToDisk="true" diskPersistent="true"/> </ehcache>copyOnRead的含义是,判断从缓存中读取数据时是返回对象的引用还是复制一个对象返回。默认情况下是false,即返回数据的引用,这种情况下返回的都是相同的对象,和 MyBatis 默认缓存中的只读对象是相同的。如果设置为true,那就是可读写缓存,每次读取缓存时都会复制一个新的实例。copyOnWrite的含义是,判断写入缓存时是直接缓存对象的引用还是复制一个对象然后缓存,默认也是false。如果想使用可读写缓存,就需要将这两个属性配置为true,如果使用只读缓存,可以不配置这两个属性,使用默认值false即可。修改缓存配置
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
集成 Redis缓存
MyBatis 项目开发者提供了 Redis 的 MyBatis 二级缓存实现,该项目名为 redis-cache,目前 只有 beta 版本,项目地址是 https://github.com/mybatis/redis-cache。
添加项目依赖
在
pom.xml文件中加入如下依赖<dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-redis</artifactId> <version>1.0.0-beta2</version> </dependency>配置
Redis在 resource 目录下新增
redis.properties文件redis.host=http://122.51.48.52 redis.port=6379 redis.connectionTimeout=5000 redis.soTimeout=5000 redis.password=950915 redis.database=0 redis.clientName=修改缓存配置
<cache type="org.mybatis.caches.redis.RedisCache"/>
脏数据的产生和避免
MyBatis 的二级缓存是和命名空间绑定的,所以通常情况下每一个 Mapper 映射文件都拥有自己的二级缓存,不同Mapper 的二级缓存互不影响。在常见的数据库操作中,多表联合查询非常常见,由于关系型数据库的设计,使得很多时候需要关联多个表才能获得想要的数据。在关联多表查询时肯定会将该查询放到某个命名空间下的映射文件中,这样一个多表的查询就会缓存在该命名空间的二级缓存中。涉及这些表的增、删、改操作通常不在一个映射文件中,它们的命名空间不同,因此当有数据变化时,多表查询的缓存未必会被清空,这种情况下就会产生脏数据。
当某几个表可以作为一个业务整体时,通常是让几个会关联的 ER 表同时使用同一个二级缓存,这样就能解决脏数据问题。