分布式搜索引擎概念
倒排序索引
Lucene Solr ElasticSearch
Lucene
Solr
ElasticSearch
ES 核心术语
Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎,可用来集中存储数据,以便对形形色色、规模不一的数据进行搜索、索引和分析。
索引index
类型type
文档document
字段fields
映射mapping
近实时NRT
节点node
shard replica
Elasticsearch 安装
从二进制安装
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.7/targz.html
下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.7.0-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.7.0-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-8.7.0-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-8.7.0-linux-x86_64.tar.gz
cd elasticsearch-8.7.0/
调整配置
调整 config/elasticsearch.yml:
path.data: /home/xianglin/Documents/elasticsearch-8.7.0/data
path.logs: /home/xianglin/Documents/elasticsearch-8.7.0/data
network.host: 0.0.0.0
新建 jvm 配置文件 config/jvm.options.d/heap_size.options ,配置堆大小:
-Xms256m
-Xmx256m
启动
./bin/elasticsearch
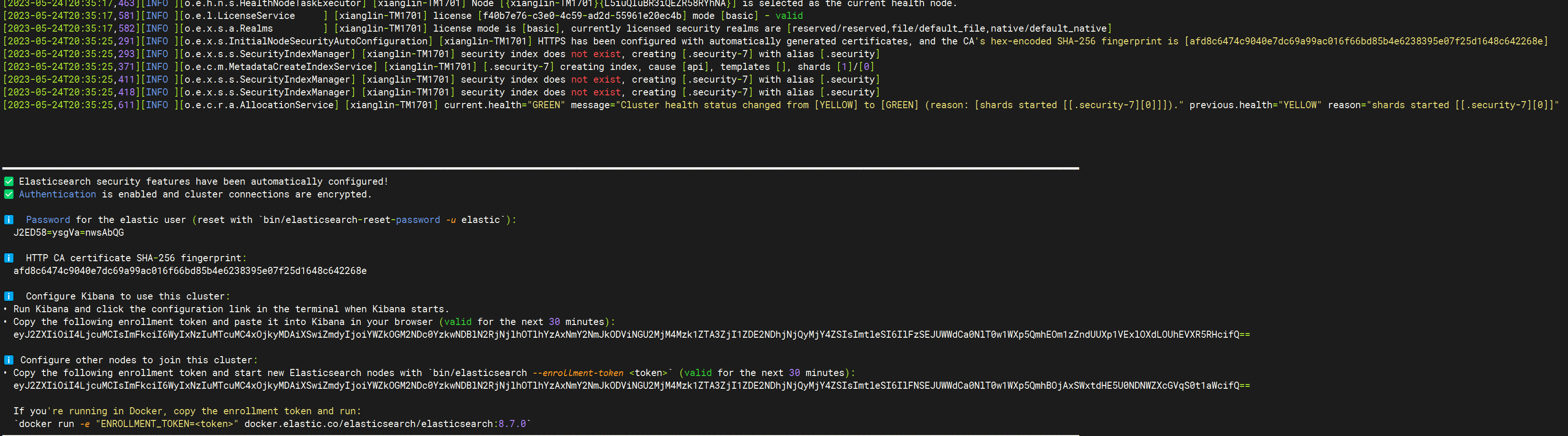
验证
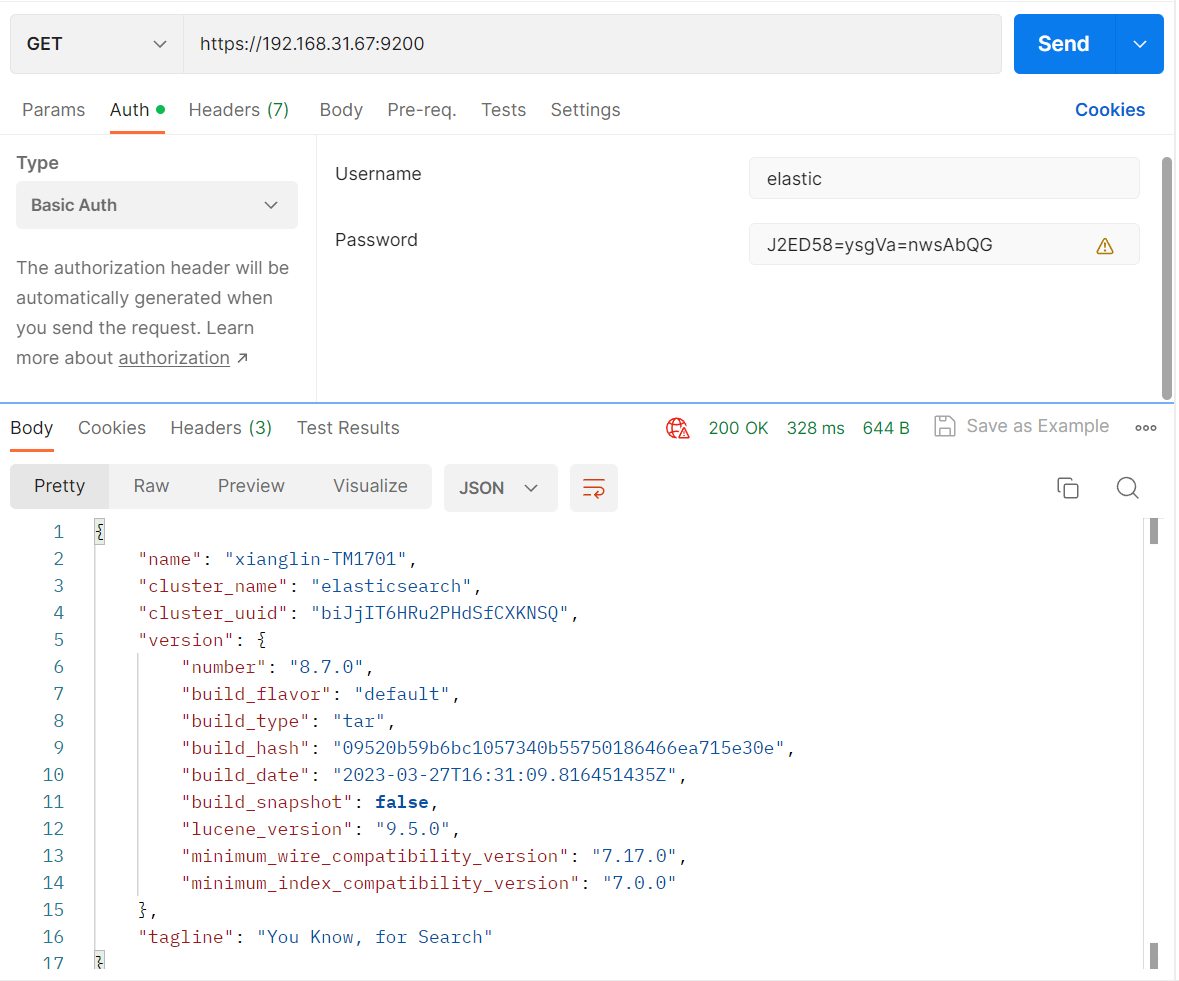
curl --cacert /home/xianglin/Documents/elasticsearch-8.7.0/config/certs/http_ca.crt -u elastic https://localhost:9200
Enter host password for user 'elastic'
或者使用 postman:
部分问题
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
参考官方解答:https://www.elastic.co/guide/en/elasticsearch/reference/8.7/vm-max-map-count.html
sudo sysctl -w vm.max_map_count=262144
从 Docker 安装
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.7/docker.html
创建 Docker 网络
docker network create elastic
启动单节点集群
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -e "network.host=0.0.0.0" --name es01 --net elastic -p 9200:9200 -it docker.elastic.co/elasticsearch/elasticsearch:8.7.1
使用 docker-compose 安装
参照 https://github.com/deviantony/docker-elk 项目
会部署 ElasticSearch、Logstash 和 Kibana 三个容器,如果暂不需要 Logstash,可以使用 docker compose up -d --scale logstash=0 命令或者直接在 docker-compose.yml 中注释掉 Logstash 相关内容。
如果需要安装 IK 分词器,需要修改 Elasticsearch 的 Dockerfile 后,执行 docker compose build 重新构建镜像
# elasticsearch/Dockerfile
ARG ELASTIC_VERSION
# https://www.docker.elastic.co/
FROM docker.elastic.co/elasticsearch/elasticsearch:${ELASTIC_VERSION:-8.17.0}
# Add your elasticsearch plugins setup here
# Example: RUN elasticsearch-plugin install analysis-icu
RUN elasticsearch-plugin install --batch https://get.infini.cloud/elasticsearch/analysis-ik/${ELASTIC_VERSION:-8.17.0}
跳过授权步骤:https://www.elastic.co/guide/en/elasticsearch/plugins/8.17/_other_command_line_parameters.html#_batch_mode
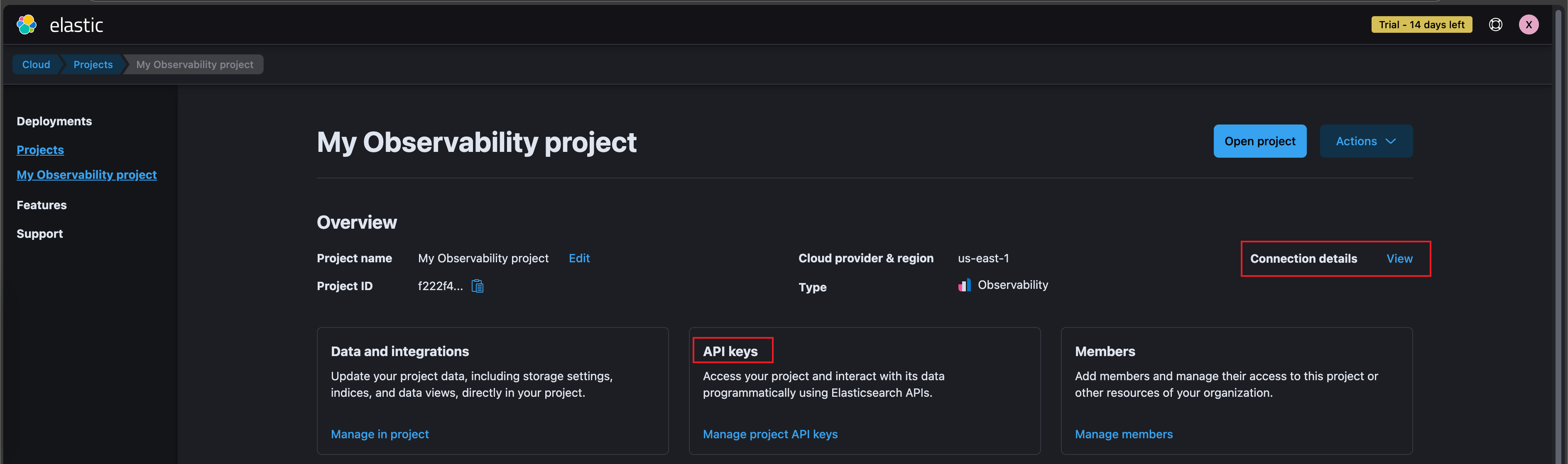
连接到 Elastic Cloud
打开 Elastic 项目控制台,获取连接信息和生成用于访问的 API 秘钥
方便学习时测试,可以赋予 API KEY 所有权限
{
"superuser_role": {
"cluster": [
"all"
],
"indices": [
{
"names": [
"*"
],
"privileges": [
"all"
],
"allow_restricted_indices": false
}
],
"applications": [],
"run_as": [],
"metadata": {},
"transient_metadata": {
"enabled": true
}
}
}
通过 Rest API 操作时携带认证信息
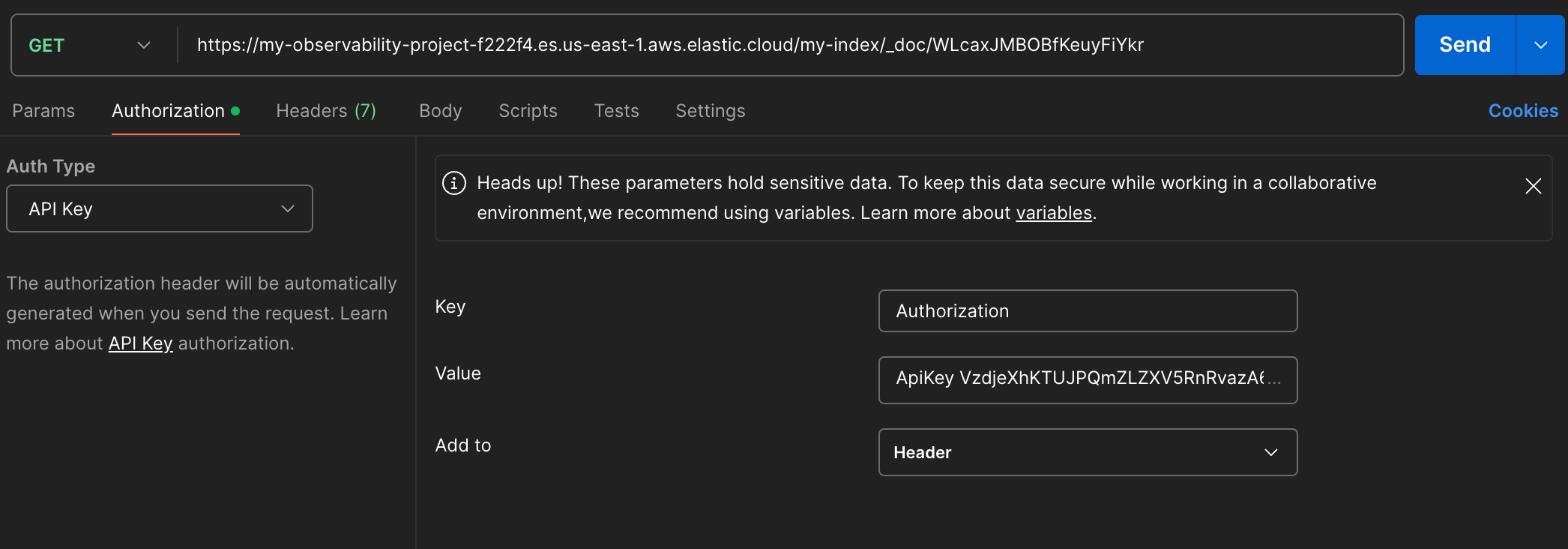
GET /my-index/_doc/WLcaxJMBOBfKeuyFiYkr HTTP/1.1
Host: my-observability-project-f222f4.es.us-east-1.aws.elastic.cloud
Authorization: ApiKey VzdjeXhKT**********************************b0tUQQ==
安装 Kibana
参考文档:https://www.elastic.co/guide/en/kibana/current/docker.html
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.7.1
浏览器访问:http://192.168.31.67:5601/app/dev_tools#/console
使用 enrollment token 连接 Elasticsearch
输入 Elasticsearch 的用户名和密码即可。
配置中文界面
参考文档:https://www.elastic.co/guide/en/kibana/current/settings.html
i18n.localeSet this value to change the Kibana interface language. Valid locales are:
en,zh-CN,ja-JP. Default:en
修改 kibana.yml 配置 i18n.locale: "zh-CN" 即可。
Elasticsearch使用
使用 Kibana Console 完成基础操作
增删改查
# 往索引 twitter 中添加一条 id 为 1 的记录
POST twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
DELETE twitter
# 按 id 更新文档
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "北京",
"province": "北京",
"country": "中国",
"location": {
"lat": "29.08",
"lon": "111.35"
}
}
# 按查询条件批量更新文档
POST twitter/_update_by_query
{
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;",
"lang": "painless",
"params": {
"city": "上海",
"province": "上海"
}
},
"query": {
"match": {
"user": "GB"
}
}
}
GET twitter/_doc/1
批量插入
POST _bulk
{"index":{"_index":"twitter"}}
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.326747"}}
{"index":{"_index":"twitter"}}
{"user":"东城区-张三","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{"index":{"_index":"twitter"}}
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{"index":{"_index":"twitter"}}
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{"index":{"_index":"twitter"}}
{"user":"朝阳区-老王","message":"Happy Birthday My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{"index":{"_index":"twitter"}}
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
Mapping 操作
GET twitter/_mapping
{
"twitter": {
"mappings": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
PUT twitter
{
"settings": {
"number_of_shards": 1
}
}
// 指定 mapping
PUT twitter/_mapping
{
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"city": {
"type": "keyword"
},
"country": {
"type": "keyword"
},
"location": {
"type": "geo_point"
},
"province": {
"type": "keyword"
},
"uid": {
"type": "long"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
基本查询
GET twitter/_search
{
"query": {
"match": {
"city": "北京"
}
}
}
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "北京"
}
},
{
"match": {
"age": "30"
}
}
]
}
}
}
GET twitter/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"city": "北京"
}
}
]
}
}
}
GET twitter/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"city": "北京"
}
},
{
"match": {
"city": "上海"
}
}
]
}
}
}
GET twitter/_count
{
"query": {
"bool": {
"should": [
{
"match": {
"city": "北京"
}
},
{
"match": {
"city": "上海"
}
}
]
}
}
}
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "北京"
}
}
]
}
},
"post_filter": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": 39.92,
"lon": 116.45
}
}
},
"sort": [
{
"_geo_distance": {
"location": "39.92,116.45",
"order": "desc",
"unit": "km"
}
}
]
}
GET twitter/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 40
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
GET twitter/_search
{
"query": {
"match": {
"message": "happy birthday"
}
}
}
# 注意大小写的自动处理
GET twitter/_search
{
"query": {
"match_phrase": {
"message": "happy birthday"
}
}
}
GET twitter/_search
{
"query": {
"match_phrase": {
"message": "happy birthday"
}
},
"highlight": {
"fields": {
"message": {}
}
}
}
聚合操作
GET twitter/_search
{
"size": 0,
"aggs": {
"age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
}
}
}
}
{
"age": {
"buckets": [
{
"key": "20.0-30.0",
"from": 20,
"to": 30,
"doc_count": 1
},
{
"key": "30.0-40.0",
"from": 30,
"to": 40,
"doc_count": 3
},
{
"key": "40.0-50.0",
"from": 40,
"to": 50,
"doc_count": 0
}
]
}
}
GET twitter/_search
{
"query": {
"match": {
"message": "happy birthday"
}
},
"size": 0,
"aggs": {
"city": {
"terms": {
"field": "city",
"size": 10
}
}
}
}
{
"city": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "北京",
"doc_count": 2
},
{
"key": "上海",
"doc_count": 1
}
]
}
}
分词操作
# 标准分词器,按空格分词
GET _analyze
{
"text": [
"Happy Birthday"
],
"analyzer": "standard"
}
{
"tokens": [
{
"token": "happy",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "birthday",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
}
]
}
# 分词后转化为小写
GET _analyze
{
"text": [
"Happy Birthday"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
{
"tokens": [
{
"token": "happy",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "birthday",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
}
]
}
分词与内置分词器
standard、simple、whitespace、stop、keyword
POST http://192.168.31.67:9200/_analyze
{
"analyzer": "standard",
"text": "这是text 文本"
}
{
"tokens": [
{
"token": "这",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "text",
"start_offset": 2,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "文",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "本",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 4
}
]
}